|
OpenFPM
5.2.0
Project that contain the implementation of distributed structures
|


|
|
OpenFPM
5.2.0
Project that contain the implementation of distributed structures
|
|
This example shows more in details the functionalities of ghost_get and ghost_put for a distributed vector.
We activate the vector_dist functionalities
Here we
Here we are creating a distributed vector following the previous example
We get an iterator and we iterate across the 4096 particles where we define their positions and properties
We redistribute the particles according to the underline decomposition
Here we synchronize the ghosts in the standard way, updating the scalar and the tensor property.
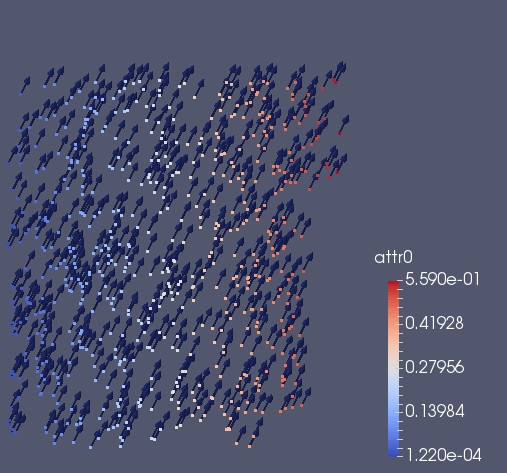
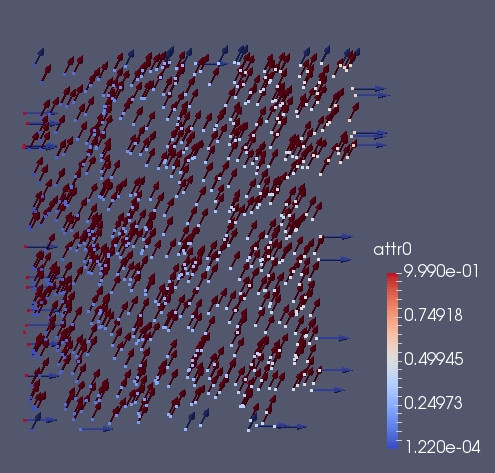
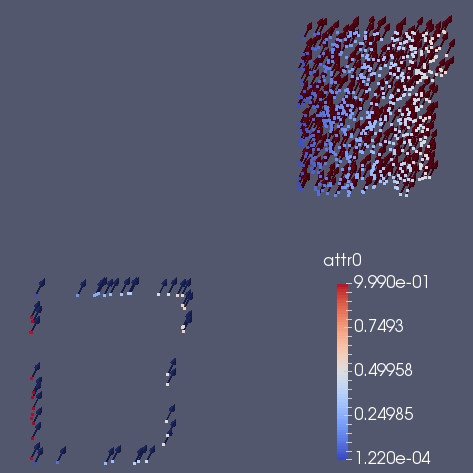
In the 2 images below we see what happen when we do a standard ghost_get Before and after. The blue arrows in the first image indicate the vector field for the real particles. In the second image instead the red arrow indicate the vector field for the real particle. The blue arrow indicate the ghosts. We can note that the blue arrow does not contain the correct vector. The reason is that when we used ghost_get we synchronized the scalar, and the tensor, but not the vector.
The first thing to do is to place the ghost in a way that the program work in parallel for sure. In order to do this we can do the following reasoning: If we have a loop over particles we distinguish two type of loops:
If the loop is of the first type (you do not loop over the neighborhood particles) ghost_get is not necessary. If I am in the second case I need a ghost_get. The second point is which property I have to synchronize ghost_get<...>(), or more practically what I have to put in the ... . To answer this we have to check all the properties that we use from the neighborhood particles and pass it to ghost_get as a list. To summarize:
This reasoning is always enough to have ghost_get function always placed correctly. For more fine tuning look at the options below
As described before every ghost_get reset the status of the ghost. In particular all the informations are lost. So for example doing a ghost_get<scalar> followed by a ghost_get<vector> will not preserve the information of the ghost_get<scalar>. This because in general ghost_get recompute the set of particles to send to the other processor based on their geometrical position. If the particles move between the ghost_get<scalar> and the the ghost_get<vector> the set of the particles sent can change between the 2 ghost_get. Merge the information between the two different set of particles would end up to be non trivial and would require to send additional information. This will make the communication inconveniently heavier. In the case the particles does not move on the other hand it would be possible to do a trivial merge of the information. The library is not able to detect automatically such cases. The information must be given explicitly. KEEP_PROPERTIES is an option that can be given to ghost_get to force to do a trivial merge in case the particles do not move. More in general such property is safe to be used in case that the particles move between ghost_get. What will happen is that the computation of the set of the particles to send will be fully skipped. OpenFPM will send the same set of particles from the previous ghost_get. Such functionality is important in case of usage of Verlet-List with radius+skin. This functionality is advanced and will be explained in a next example.
Because the option KEEP_PROPERTIES has the functionality to keep the properties and skip the labelling. The option KEEP_PROPERTIES is also names SKIP_LABELLING. The two options are exactly equivalents.
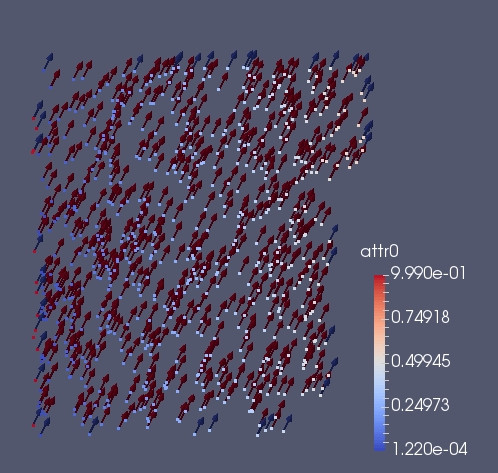
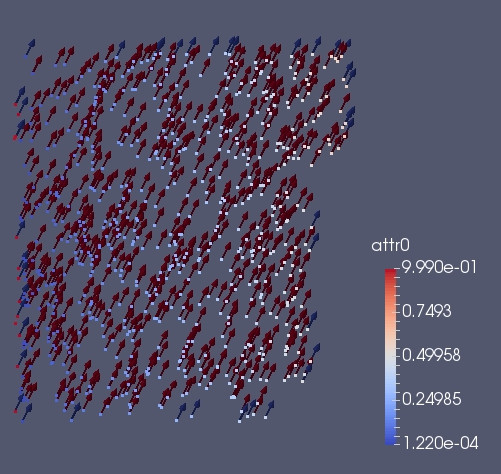
In the picture below we can see what happen when from the previous situation, we do a ghost_get with KEEP_PROPERTIES for the vector field. The vector change pointing to the right direction. On the other hand also the scalar (The dot color)is kept and the information is not destroyed.
ghost_get in general send automatically the information about position. If we are sure that the particles position did not change its position we can use the option NO_POSITION, to avoid to send the positional informations. With the only purpose to show what happens we shift the particle position of the ghost parts by one. We also force the vector to point to the opposite direction.
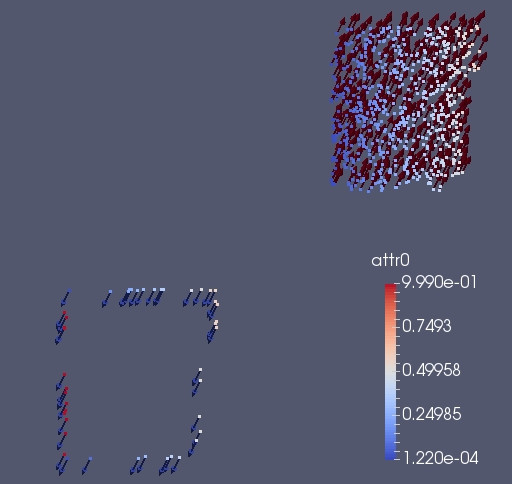
Doing a ghost_get with KEEP_PROPERTY and NO_POSITION, it will updates the information of the vectors, but the position will remain the same.
We can restore the positioninformation doing a ghost_get without NO_POSITION
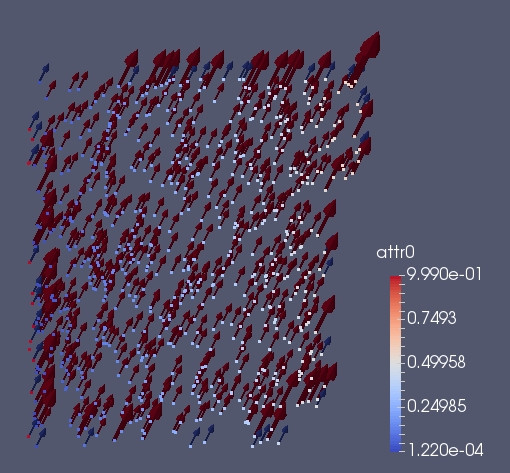
ghost_put is another particular function. It work similarly to ghost_get but in the inverted direction. In particular it take the information from the ghost particles and it send the information back to the real particles. How to merge the information back to the real particles is defined by an operation.
In this particular case we scatter back the information present in the ghost.
Once the particles are received back we add_ such contributions to the real particles. A typical real application of such functionality is in the case of symmetric interactions
As we can see from the image below some of red particles near the ghost has a bigger arrow
At the very end of the program we have always de-initialize the library
 1.9.1
1.9.1